Файловые системы
Первые коммерческие компьютерные системы использовались в основном для ведения бухгалтерии: дебет, кредит, ведомости заработной платы и т.д. Эту работу предприятие обязано делать. Следовательно, оправдать стоимость компьютерной системы было несложно. Затраты ручного труда, например, на ведение ведомостей по заработной плате или выписывание счетов, были столь велики, что автоматическая система, которая могла выполнять эти функции, быстро окупалась.
Поскольку эти системы выполняли обычные функции работы с документами, они были названы системами обработки данных. Неудивительно, что программисты и аналитики, разрабатывавшие эти системы, подражали в своих программах тем операциям, которые прежде выполнялись вручную. Так например, компьютерные файлы соответствовали папкам для бумаг, и компьютерный файл содержал ту информацию, которая вполне могла бы лежать в одной обычной папке.
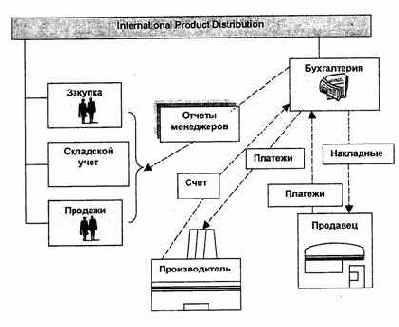
Рис. 1.1. Поиск информации IPD
На рис. 1.1, 1.2 представлены некоторые файлы и образцы данных первой файловой. Каждая таблица представляет один файл системы. Таким образом, мы видим файлы CUSTOMER (КЛИЕНТ), SALES-REPRESENTATIVE (ТОРГОВЫЙ-АГЕНТ), PRODUCT (ТОВАР) и т.д. Каждая строка соответствует одной записи в файле. Так, файл PRODUCT содержит три записи. Каждая из этих записей относится к отдельному товару. Элементарные группы данных или поля файла PRODUCT таковы: PROD-ID (ИД-ТОВАРА), PROD-DESC (ОПИСАНИЕ-ТОВАРА), MANUPACTR-ID (ИД-ИЗГОТОВИТЕЛЯ), COST (ЗАКУПОЧНАЯ ЦЕНА) и PRICE (ЦЕНА ПРОДАЖИ).
CUSTOMER